

你是否在寻找一种从网站收集数据的方法?这可以通过编码来完成。下面的文章强调了如何完成这一工作,重点是使用Python。
互联网是研究人员、企业和政府组织的最重要的数据来源之一。每天在互联网上产生的数据超过2.5万亿字节,对大多数企业来说,数据不再是一个问题。主要问题是如何收集数据以及如何处理这些数据。在这篇文章中,我们的重点是帮助你收集数据,同时你要理清你需要这些数据的原因。
通常,当从网站收集数据在这一点上被提及时,我们希望你把注意力放在自动化上。这是因为,如果不把这个过程自动化,你就不可能大规模地收集任何合理数量的数据。
网络抓取:自动收集网络数据的方法
从介绍中,我提到网络数据提取是以自动方式完成的,对吗?那么,这个过程被称为网络抓取。网络抓取是使用被称为网络抓取器的专门的网络机器人来自动收集网络数据的过程。
只要数据点的位置是已知的,或者数据有一个可以用来识别的模式,这个过程就可以用于从网络上大规模地收集数据。虽然该方法相当有帮助,而且速度很快,但重要的是你要知道,网站不支持它。作为一个编码员,你可以开发自定义代码,专门从网站上收集重要的数据点。
什么类型的数据可以从网站上收集到?
重要的是你要知道,互联网上的各种数据都可以被抓取,包括文本、图像、视频,甚至音频文件。下面是一些从互联网上被抓取最多的数据。
产品数据
产品数据,如产品名称、价格、评级、规格及其相关的客户评论,是当今互联网上被抓取最多的一些数据。你可以从电子商务商店,如亚马逊、沃尔玛、eBay、AliExpress和其他数以百万计的在线电子商务商店抓取产品细节。
领先数据
电子邮件、电话号码和姓名是你需要与潜在客户交谈的一些关键细节,所有这些都可以在网上以任何规模获得。LinkedIn是一个受欢迎的线索数据来源,但它并不孤单。
你可以从Twitter、Facebook和众多用户发布电子邮件地址和电话号码的在线论坛中产生线索。在这种情况下,正则表达式(Regex)被大量使用。
用户的意见和感想
由于人们越来越愿意在网上讨论很多问题,所以有很多数据你可以分析社会问题。许多企业、政治机构和研究人员在社交媒体上抓取用户生成的数据,以大规模地了解用户的情绪。Facebook和Twitter是最流行的抓取社会用户生成内容的网站。
其他通用数据
政府记录、来自传感器和物联网设备的自动生成的数据、来自研究的数据等等,也是一些从互联网上抓取最多的数据。还有很多,其中一些你甚至会发现很难对它们进行分类。
要知道,任何网上公开的数据都可以用网络抓取器抓取到。公开可用数据的使用情况和重要性是由对数据感兴趣的人决定的。
如何使用Python从网站上抓取数据
在本节中,我们将向你展示如何使用Python编程语言从网站收集数据。如果你是其他语言的编码者,网络上也有关于大多数语言的丰富信息。
为了使用Python从网站上收集数据,你需要基本的Python编码技能,然后学习如何利用特定的Python网络抓取库。虽然你可以使用Python标准库中的模块来进行抓取,但你会发现这很困难,因此,你最好使用第三方库。让我们来看看下面这些库中的一些。
用于网络抓取的Python库
目前,Python编程语言对网络抓取有最好的库支持–而且总有一种工具可以满足你的网络抓取需要。下面是作为一个对网络抓取感兴趣的Python开发者的3种选择。
Requests and BeautifulSoup
Requests是一个HTTP库,用于发送网络请求并获得响应。它用于下载网页的HTML。另一方面,BeautifulSoup是建立在一个分析器上的,使从HTML文档中提取数据变得容易。
有了这两种方法,你可以抓取普通的HTML网页,只要它们不依赖于JavaScript的渲染。如果需要JavaScript的执行和渲染,你将不得不使用另一种替代方法。
Scrapy
Scrapy基本上是一个用于网络爬取和抓取的框架。它是一个更高级的工具,并带有网络抓取所需的大部分工具。它甚至还支持中间件,使其成为一个更强大的解决方案。它也比使用Request和BeautifulSoup快。然而,它不支持JavaScript渲染工具,对初学者来说,可能有点难学。
Selenium
Selenium是一个网络浏览器驱动程序。它的作用是使网络浏览器自动化,至于你用它来做什么,则取决于你。在我们的案例中,我们用它来渲染页面,因为它们出现在真正的用户面前,以抓取重要的数据。
这是一个流行的工具,用于从依赖Javascript渲染内容的网页中抓取数据。然而,它可能很慢,因此,你应该只用它来抓取Javascript页面。对于普通网页,请使用上述两个选项中的任何一个。
与Python网络抓取有关的问题
重要的是要知道,使用定制的网络抓取器,你将面临很多问题。这是因为大多数网站不喜欢被抓取,并在其反垃圾邮件系统中嵌入了反抓取系统。你将需要通过使用轮流代理来掩盖你的IP地址,并超过网站设置的请求限制,从而避免被屏蔽。
对于使用验证码的网站,你将需要利用反验证码。同样流行的是使用其他技术,如请求之间的随机延迟和设置/改变用户代理和其他相关请求头。
然而,除了避免区块的问题外,你还需要考虑网站结构的变化,这也是大多数网络抓取器需要维护的原因。大多数网站经常改变它们的布局,当它们改变时,用于从它们身上抓取数据的网络抓取器就会中断,因为解析是硬编码的。
使用Python抓取数据的步骤与实例
让我在实践中告诉你,如何使用Python收集网络数据。在本指南中,我们将使用Requests和BeautifulSoup库来做这件事。与所有的编码指南一样,需要一个需要解决的问题。在这个例子中,我们将开发一个网络爬虫,从亚马逊产品页面收集产品名称和价格。
第1步:安装必要的库房
如前所述,我们需要使用第三方库来使事情变得更容易,我们选择的选项是Requests和BeautifulSoup的组合。要安装Requests,请在命令提示符下运行以下命令。
“pip install requests”
要安装BeautifulSoup,请运行以下命令。
“pip install bs4”
在你运行上面的命令之前,预计你已经安装了Python 3。如果运行成功,你可以继续进行下一步。
第2步:检查产品页面的HTML以识别元素
网页是用HTML构建的,并使用CSS进行样式设计。你在网页上看到的内容是由HTML元素构成的。为了从一个页面中提取数据,你需要知道它所包含的元素以及如何唯一地识别它。
你可以通过查看源代码来做到这一点。要查看源代码,请右击并点击,”view source code“。下面是截图,突出显示了带有产品名称的元素。
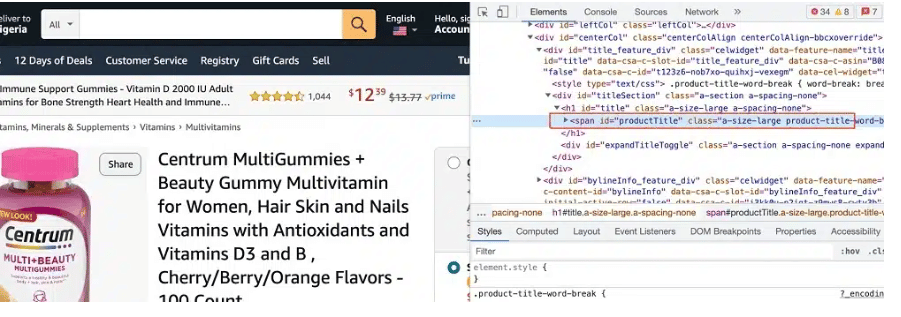
正如你在上面看到的,产品名称被包围在一个 “span“元素中,其ID为productTitle。HTML元素的ID是唯一的,所以我们可以用它们作为CSS选择器来掌握亚马逊上的产品名称。对于产品价格,下面是其HTML元素的截图。
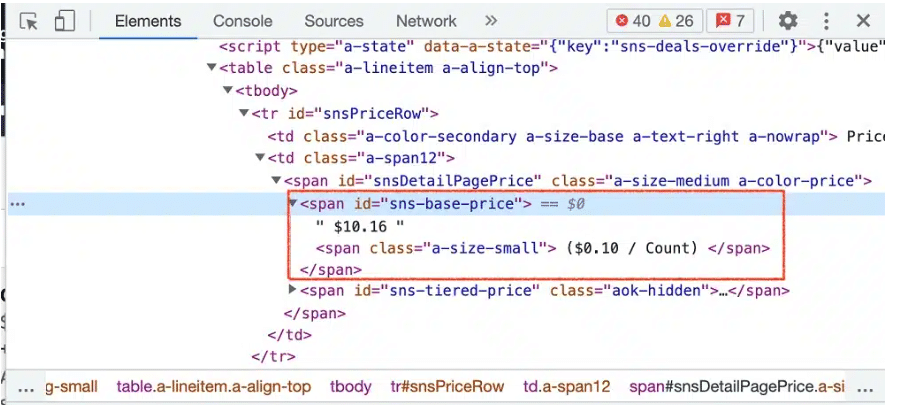
正如你在上面看到的,价格也被包围在一个span元素中,ID为sns-base-price。有了这个,我们已经得到了我们的抓取所需的CSS选择器,如下。
产品名称:productTitle
产品价格:sns-base-price
第3步:编码请求逻辑
网络抓取器基本上是请求HTML文档,然后从其中解析出所需的数据。第一步实际上是请求一个页面的HTML,你使用请求来做这个。
下面是一段代码,告诉你如何使用产品的URL请求产品页面。对于这个逻辑,我们实际上将用户代理头设置为普通的,因为如果你的用户代理是可疑的,亚马逊会阻止你。
import requests
from bs4 import BeautifulSoup
HEADERS = ({'User-Agent':
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36',
'Accept-Language': 'en-US, en;q=0.5'})
product_URL = "https://www.amazon.com/Centrum-Multigummies-Beauty-Gummy-Multivitamin/dp/B08YS6M82M/?_encoding=UTF8&pd_rd_w=nYgXc&content-id=amzn1.sym.6479f04b-39f5-47c1-9063-123e82e2ba82&pf_rd_p=6479f04b-39f5-47c1-9063-123e82e2ba82&pf_rd_r=261RCJHQ0G9Q7R63SBKZ&pd_rd_wg=1q9qj&pd_rd_r=f10dc5ca-aa97-4683-8fee-c564fd326a8f&ref_=pd_gw_trq_ed_dl30varo"
req = requests.get(product_URL, headers=HEADERS)
print(req.text)
第四步:创建BeautifulSoup和提取数据
如果你运行上述代码,你会看到它在屏幕上打印出整个页面的HTML。但我们所追求的不是原始的HTML。我们要的只是产品的名称和价格。为此,我们使用BeautifulSoup工具来实现这一点。下面是这方面的代码。
#extract product name
try:
product_title = soup.find("span", attrs={"id":'productTitle'}).text
except AttributeError:
product_title = ""
print(product_title)
#extract product price
try:
product_price = soup.find("span", attrs={'id':'sns-base-price'}).string.strip()
except AttributeError:
product_price = ""
print(product_price)
第5步:重构代码
下面是完整的代码,现在的结构是一个类和方法。
import requests
from bs4 import BeautifulSoup
class ProductScraper:
def __init__(self, url):
self.product_URL = url
self.product_title = ""
self.product_price = ""
self.page_source = ""
def downlaod_page(self):
HEADERS = ({'User-Agent':
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36',
'Accept-Language': 'en-US, en;q=0.5'})
self.page_source = requests.get(self.product_URL, headers=HEADERS)
def get_product_title(self):
try:
product_title = self.page_source.find("span", attrs={"id": 'productTitle'}).text
except AttributeError:
product_title = ""
self.product_title = product_title
def get_product_price(self):
try:
product_price = self.page_source.find("span", attrs={'id': 'sns-base-price'}).string.strip()
except AttributeError:
product_price = ""
self.product_price = product_price
url = "https://www.amazon.com/Centrum-Multigummies-Beauty-Gummy-Multivitamin/dp/B08YS6M82M/?_encoding=UTF8&pd_rd_w=nYgXc&content-id=amzn1.sym.6479f04b-39f5-47c1-9063-123e82e2ba82&pf_rd_p=6479f04b-39f5-47c1-9063-123e82e2ba82&pf_rd_r=261RCJHQ0G9Q7R63SBKZ&pd_rd_wg=1q9qj&pd_rd_r=f10dc5ca-aa97-4683-8fee-c564fd326a8f&ref_=pd_gw_trq_ed_dl30varo"
c = ProductScraper(url)
c.downlaod_page()
c.get_product_title()
c.get_product_price()
print(c.product_title)
print(c.product_price)
从网站收集数据的常见问题
1.从网站上收集数据是否被允许?
通过自动化手段收集数据的行为是大多数网站所不允许的。这要么是因为网络抓取者发出的请求太多,要么是因为他们不希望你从他们的平台上免费收集数据。
而对于那些受欢迎的网站,他们有反抓取系统,使你难以从他们的平台上收集数据。即使有了这些,只要你抓取的数据对所有用户公开,网络抓取仍然不违法。
2.从网站收集数据的最佳方法是什么?
一般来说,你已经可以知道,网络抓取是收集网站数据的最佳方法。但其中什么方法是最好的呢?答案主要取决于你的编码技能。
如果你是一个编码员,你可以简单地开发一个自定义的抓取器,或者使用一个已经制作好的抓取器,以避免重新发明轮子和绕过与网络抓取有关的头痛问题。对于非编码人员,你可以简单地寻找无编码抓取工具,因为它们也很完美。
总 结
毫无疑问,数据的重要性怎么强调都不为过。而随着互联网上的数据量越来越大,人们对收集这些数据的兴趣也就不言而喻了。
你需要知道的一件事是,使用正确的网络数据提取工具会有很大的帮助。如果你发现自己开发一个或使用一个无代码的抓取工具有困难,你可以简单地利用专业的数据服务,可以帮助你从网络上获得所有你需要的数据。