

网页抓取变得越来越流行,现在是IT界的一个趋势性话题。因此,有几个库帮助你从网站上爬取数据。在这里,你将学习如何使用最流行的网络爬取库之一,在PHP中建立一个网页爬取器。
在本教程中,你将学习PHP中的网页爬取的基础知识。然后是如何绕过最流行的反爬取系统,学习更高级的技术和概念,如并行爬取和无头浏览器。
按照本教程,你将成为用PHP进行网络爬取的专家。让我们不要浪费更多的时间,用PHP建立我们的第一个爬取器。
首要条件
如果你的系统中没有安装这些东西,你可以通过上面的链接下载。
然后,你还需要以下Composer库。
voku/simple_html_dom>= 4.8
你可以用以下命令将其添加到你的项目的依赖关系中。
![]()
此外,你还需要内置的cURLPHP库。cURL带有curl-extPHP扩展,它在大多数的PHP包中都自动存在并启用。如果你安装的PHP包不包括curl-ext,你可以按照这里的解释安装它。
现在让我们进一步了解这里提到的依赖性。
简 介
voku/simple_html_dom是Simple HTML DOM Parser项目的一个分支,它用DOMDocument和其他现代PHP类代替了字符串操作。voku/simple_html_dom拥有近200万的安装量,是一个快速、可靠、简单的库,用于解析HTML文档和在PHP中执行Web刮擦。
curl-ext是一个在PHP中启用cURLHTTP客户端的PHP扩展,它允许你在PHP中执行HTTP请求。
你可以在这个GitHub repo中找到演示网络爬取器的代码。克隆它并通过以下命令安装项目的依赖性。
![]()
跟随本教程,学习如何在PHP中建立一个网络爬取器的应用!
在PHP中进行基本的网页爬取
在这里,你将看到如何在https://scrapeme.live/shop/,一个被设计为爬取目标的网站上进行网络爬取。
正如你所看到的,scrapeme.live只不过是一个简单的分页的口袋妖怪启发的产品列表。让我们用PHP建立一个简单的网络爬取器,抓取网站并从所有这些产品中爬取数据。
首先,你需要下载你要爬取的页面的HTML。你可以用cURL在PHP中轻松地下载一个HTML文档,如下所示。
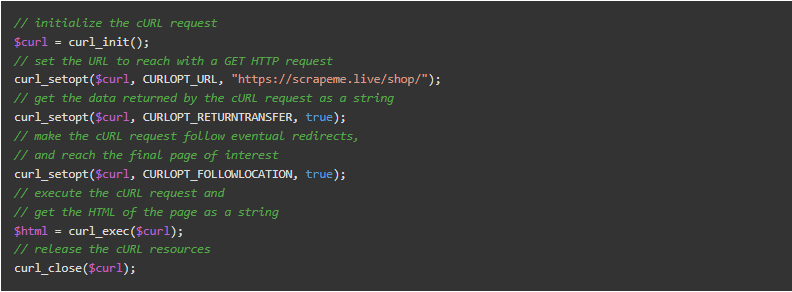
现在,你有了https://scrapeme.live/shop/页面的HTML,存储在$html变量中。用str_get_html()函数将其加载到HtmlDomParser实例中,如下所示。
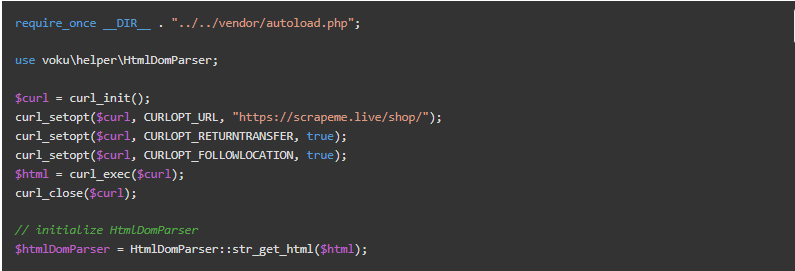
现在你可以使用HtmlDomParser来浏览HTML页面的DOM并开始提取数据。
现在让我们检索所有分页链接的列表,以抓取整个网站部分。右键单击分页数字HTML元素,选择 “检查 “选项。
在这一点上,浏览器应该打开一个DevTools窗口或部分,并突出显示DOM元素,如下图所示。
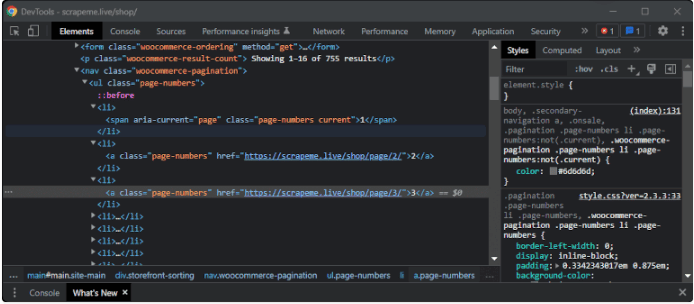
在WebTools窗口中,你可以看到page-numbersCSS类标识了分页的HTML元素。请注意,一个CSS类并不能唯一地识别一个HTML元素,许多节点可能有相同的类。这正是scrapeme.live页面中的page-numbers的情况。
因此,如果你想用一个CSS选择器来挑选DOM中的元素,你应该把这个CSS类和其他选择器一起使用。特别是,你可以使用HtmlDomParser和.page-numbers这个CSS选择器来选择页面上的所有分页HTML元素。然后,通过它们进行迭代,从href属性中提取所有需要的URL,如下所示。
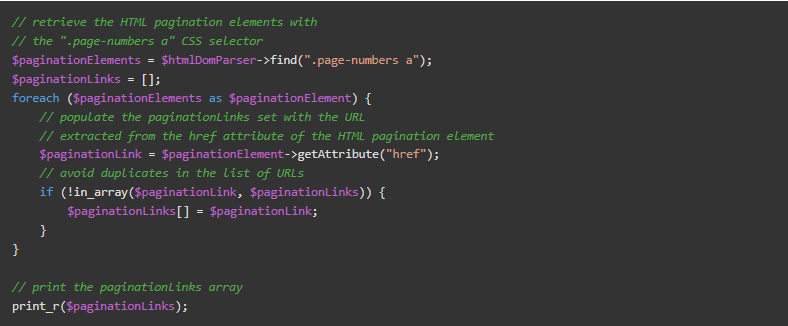
注意,find()函数允许你根据CSS选择器提取DOM元素。另外,考虑到分页元素在网页上被放置两次,你需要定义自定义逻辑以避免 $paginationLinks数组中的元素重复。
如果执行,这个脚本将返回。
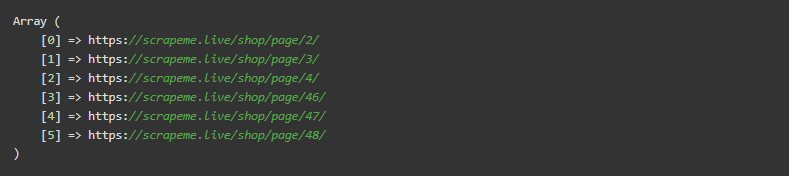
如图所示,所有的URL都遵循相同的结构,并以最后的数字为特征,指定分页号。如果你想遍历所有页面,你只需要与最后一页相关的数字。检索方法如下。

$highestPaginationNumber将包含 “48”。
现在,让我们检索一下与单个产品相关的数据。同样,右击一个产品,用 “检查 “选项打开DevTools窗口。这是你应该得到的东西。
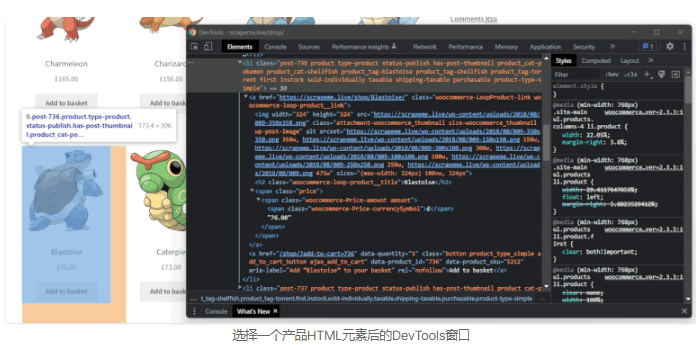
正如你所看到的,一个产品由一个li.product的HTML元素组成,包含一个URL,一个图片,一个名称和价格。这些产品信息被分别放在a、img、h2、span等HTML元素中。你可以用下面的HtmlDomParseras提取这些数据。
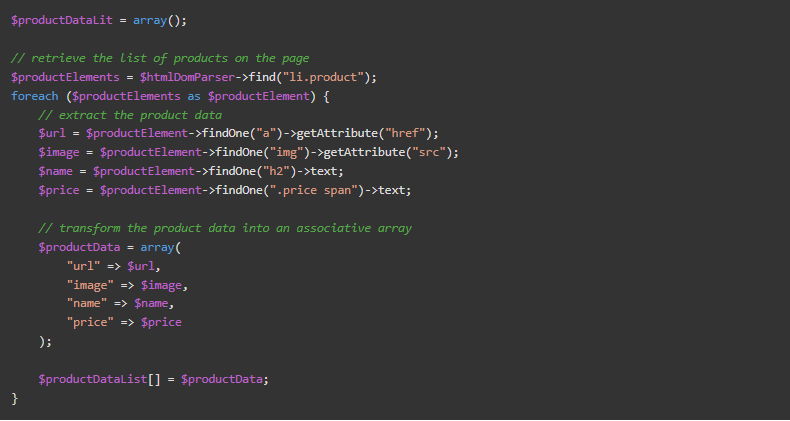
这个逻辑提取了一个页面上的所有产品数据,并将其保存在$productDataList数组中。
现在,你只需要在每个页面上进行迭代,并应用上面定义的爬取逻辑。
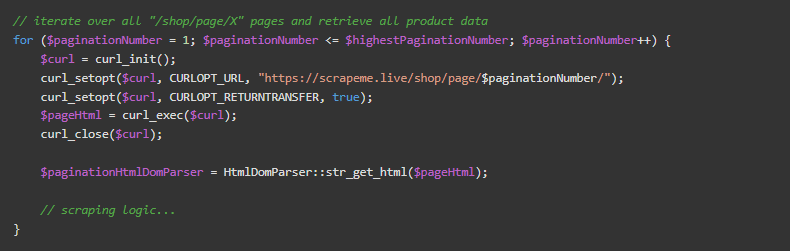
你刚刚学会了如何在PHP中建立一个简单的网络爬取器!
如果你想看一下这个脚本的全部代码,你可以在这里找到。运行它,你会检索到以下数据。
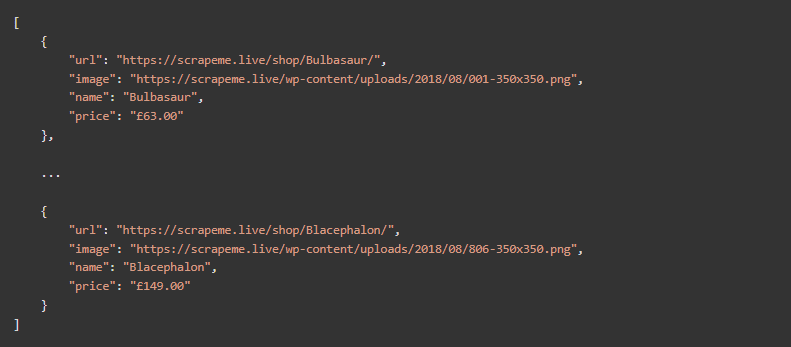
恭喜你!你刚刚自动提取了所有的产品数据。你刚刚自动提取了所有的产品数据!
避免被封锁
上面的例子使用了一个为爬取而设计的网站。提取所有数据是小菜一碟,但不要被这一点所迷惑!爬取网站并不总是那么容易,你的脚本可能被拦截和封锁。找出如何防止这种情况发生!
有几种可能的防御机制来防止脚本访问网站。这些技术试图根据用户的行为识别来自非人类或恶意用户的请求,并相应地阻止它们。
绕过所有这些反窃取系统并不总是容易的。然而,你通常可以通过两个简单的解决方案来避免它们中的大多数:普通的HTTP头和网络代理。现在让我们仔细看看这两种方法。
1.使用常见的HTTP头来模拟真实的用户
许多网站会阻止那些看起来不是来自真实用户的请求。另一方面,浏览器会设置一些HTTP标头。确切的标头在不同的厂商之间会有变化。因此,这些反窃取系统希望这些头信息能够存在。因此,你可以通过设置适当的HTTP头来避免阻断。
具体来说,你应该始终设置的最关键的标头是User-Agent标头(以下简称UA)。它是一个字符串,用于识别HTTP请求来源的应用程序、操作系统、供应商和/或应用程序版本。
默认情况下,cURL会发送curl/XX.YY.ZZUA头,这使得请求很容易被识别为一个脚本。你可以用cURL手动设置UA头,方法如下。
![]()
例子:

这行代码设置了最新版本的谷歌浏览器目前使用的UA。它使cURL请求更难被识别为来自脚本。
你可以很容易地在网上找到一个有效的、最新的、可信赖的UA头的列表。在大多数情况下,设置HTTP UA头信息就足以避免被屏蔽了。如果这还不够,你可以用cURL发送其他的HTTP头信息,如下所示。

例子:

2.使用网络代理来隐藏你的IP
反爬取系统往往会阻止用户在短时间内访问许多网页。主要的检查是看请求来自哪个IP。如果同一个IP在短时间内发出许多请求,它就会被阻止。换句话说,为了防止对一个IP的封杀,你必须找到一种方法来隐藏它。
最好的方法之一是通过代理服务器。网络代理是您的机器和互联网上其他计算机之间的一个中间服务器。当通过代理服务器执行请求时,目标网站将看到代理服务器的IP地址而不是你的。
网上有几个免费的代理,但大多数是短暂的,不可靠的,而且经常无法使用。你可以用它们进行测试。但是,你不应该依赖它们来制作脚本。
另一方面,付费代理服务更可靠,通常带有IP轮换功能。这意味着,代理服务器暴露的IP将随着时间或每次请求的变化而频繁变化。这使得服务提供的每个IP更难被禁止,即使发生这种情况,你也会在短时间内得到一个新的IP。
你可以用cURL设置一个网络代理,方法如下:

例子:

对于大多数网络代理,在第一行设置代理的URL就足够了。CURLOPT_PROXYTYPE可以取以下值。CURLPROXY_HTTP(默认),CURLPROXY_SOCKS4,CURLPROXY_SOCKS5,CURLPROXY_SOCKS4A,或CURLPROXY_SOCKS5_HOSTNAME。
你刚刚学会了如何避免被屏蔽。现在让我们来探讨一下如何使你的脚本更快。
并行爬取
在PHP中处理多线程是很复杂的。有几个库可以支持你,但在PHP中执行并行爬取的最简单和最有效的解决方案不需要任何库。
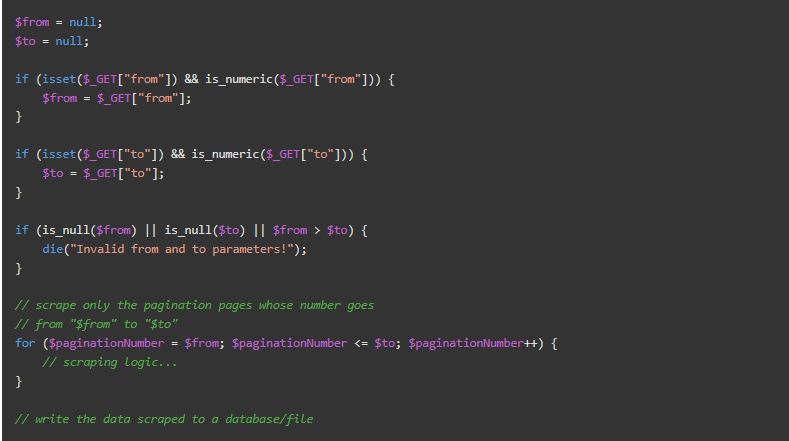
这种并行爬取的方法背后的想法是使爬取脚本可以在多个实例上运行。这可以通过使用HTTP GET参数来实现。
考虑一下前面介绍的分页的例子。你可以修改脚本,使其在较小的块上工作,然后并行地启动几个脚本实例,而不是让脚本在所有页面上迭代。
你所要做的就是向脚本传递一些参数来定义块的边界。你可以通过引入以下两个GET参数轻松实现这一目标。
现在,你可以通过在浏览器中打开这些链接来启动脚本的多个实例。

这些实例将并行运行,并同时爬取网站。你可以在这里找到这个新版本的爬取脚本的全部代码。
这就是你的成果!你刚刚学会了如何通过网络爬取从一个网站上平行提取数据。
能够并行地爬取一个网站已经是一个很大的进步,但在你的PHP网络爬取器中还有许多其他的高级技术可以采用。让我们来看看如何将你的网络爬取脚本提高到一个新的水平。
高级技术
请记住,并非网页上所有感兴趣的数据都直接显示在浏览器中。一个网页还包括元数据和隐藏元素。要访问这些数据,可在网页的一个空白部分上点击右键,然后点击 “查看页面源”。
在这里你可以看到一个网页的全部DOM,包括隐藏的元素。详细来说,你可以在元HTML标签中找到关于网页的元数据。此外,重要的隐藏数据可能被存储在<input type="hidden"/>元素中。
同样地,有些数据可能已经通过隐藏的HTML元素存在于页面上。而它只有在某个特定事件发生时才会被JavaScript显示出来。即使你在页面上看不到这些数据,它仍然是DOM的一部分。因此,你可以用HtmlDomParser检索这些隐藏的HTML元素,就像你检索可见节点一样。
另外,请记住,一个网页不仅仅是它的源代码。网页可以在浏览器中发出请求,通过AJAX异步检索数据,并相应地更新其DOM。这些AJAX调用通常会提供有价值的数据,你可能需要从你的网页爬取脚本中调用它们。
要嗅出这些调用,你需要使用浏览器的DevTools窗口。右键点击网站的一个空白部分,选择 “检查”,然后到达 “网络 “标签。在 “Fetch/XHR “标签中,你可以看到网页执行的AJAX调用列表,如下图所示。
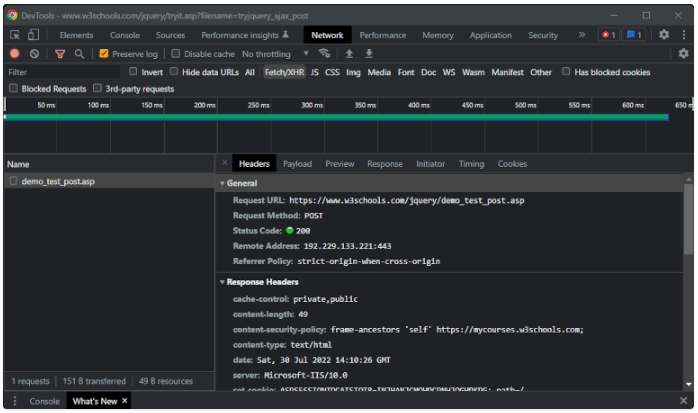
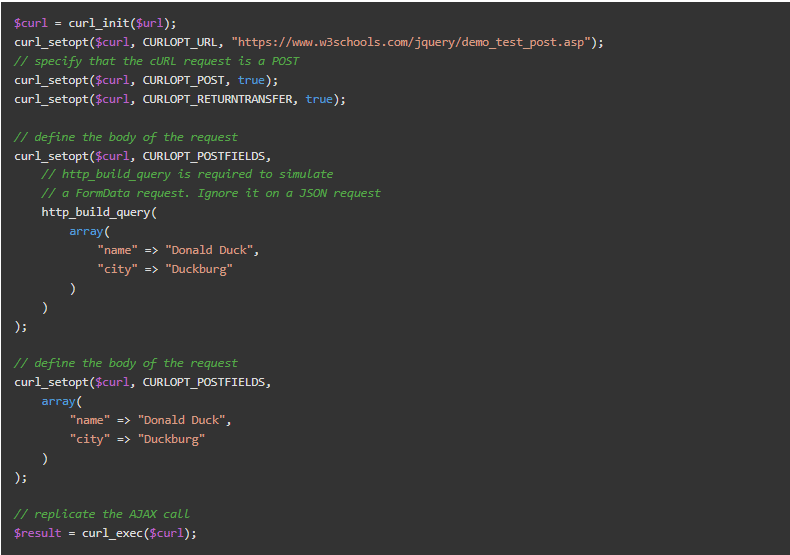
探索所选AJAX请求的所有内部标签,了解如何执行AJAX调用。具体来说,你可以用cURL复制这个POST的AJAX调用,如下所示。
无头浏览器
嗅探和复制AJAX调用有助于从网站上以编程方式检索因用户互动而加载的数据。这些数据不是网页源代码的一部分,不能在从标准GETcURL请求获得的HTML元素中找到。
然而,复制所有可能的交互,嗅探AJAX调用,并在你的脚本中调用它们,是一种麻烦的方法。有时,你需要定义一个脚本,它可以像人类用户那样通过JavaScript与页面互动。你可以用无头浏览器来实现这一点。
如果你不熟悉这个概念,无头浏览器是一个没有图形用户界面的网页浏览器,它通过代码提供对网页的自动控制。PHP中最流行的提供无头浏览器功能的库是chrome-php和Selenium WebDriver。
其他库
当涉及到网络抓取时,你可能采用的其他有用的PHP库是。
总 结
现在,你学到了关于在PHP中执行网络抓取的所有知识,从基本抓取到高级技术。如上所示,在PHP中建立一个能够抓取网站并自动提取数据的网页爬取器并不难。你所需要的是正确的库,这里我们看了一些最流行的库。
另外,你的网页爬取器应该能够绕过反爬取系统,可能要检索隐藏的数据,或者像人类用户一样与网页互动。在本教程中,你也学到了如何做到这些。

