

Javascript和网络抓取都在兴起。我们将把它们结合起来,在NodeJS中使用Javascript从头开始建立一个抓取器和爬虫。
避免阻塞是网站爬取的一个重要部分。所以我们也将添加一些功能来帮助这方面的工作。最后,由于Node的事件循环,将任务并行化,使之更快。
跟随本教程学习如何用Node和Javascript进行网络爬取!
首要条件
为了使代码工作,你需要安装Node(或nvm)和npm。一些系统已经预装了它。之后,通过运行npm install来安装所有必要的库。它将创建一个包含所有依赖项的package.json文件。

JS爬取工具介绍
我们使用的是Node v12,但你可以随时检查每个功能的兼容性。
Axios是一个 “基于承诺的HTTP客户端”,我们将用它来从一个URL中获取HTML。它允许几个选项,如头文件和代理,我们将在后面介绍。如果你使用TypeScript,他们包括 “定义和Axios错误的类型保护”。
Cheerio是一个 “快速、灵活和精简的核心jQuery实现 “的Javascript库。它可以让我们使用选择器找到DOM节点,获得文本或属性,以及其他许多东西。我们将把HTML传递给cheerio,然后查询它以提取数据。就像我们在浏览器环境中那样。
Playwright是一个Node.js库,用一个单一的API来自动化Chromium、Firefox和WebKit”。当Axios不够用时,我们将使用无头浏览器获得HTML。然后它将解析内容,执行Javascript并等待异步内容的加载。
Node JS适合用于网页爬取吗?
正如你在上面看到的,工具是可用的,技术也是巩固的。所有这些都被广泛使用并得到适当的维护。
除了这些,每一种都有几个替代品。还有很多专注于一项任务的,如表格爬取器。Javascript网络爬取的生态系统是巨大的
如何用Javascript进行网络爬取?
我们首先需要的是HTML。我们为此安装了Axios,其用法很简单。我们将使用scrapeme.live作为例子,这是一个准备用于爬取的假网页。

很好!然后,我们可以用cheerio查询我们现在想要的两样东西:分页链接和产品。我们将在打开Chrome DevTools的情况下查看该页面,以了解如何做到这一点。所有现代的网络浏览器都提供了类似这样的开发者工具。挑选你最喜欢的吧。
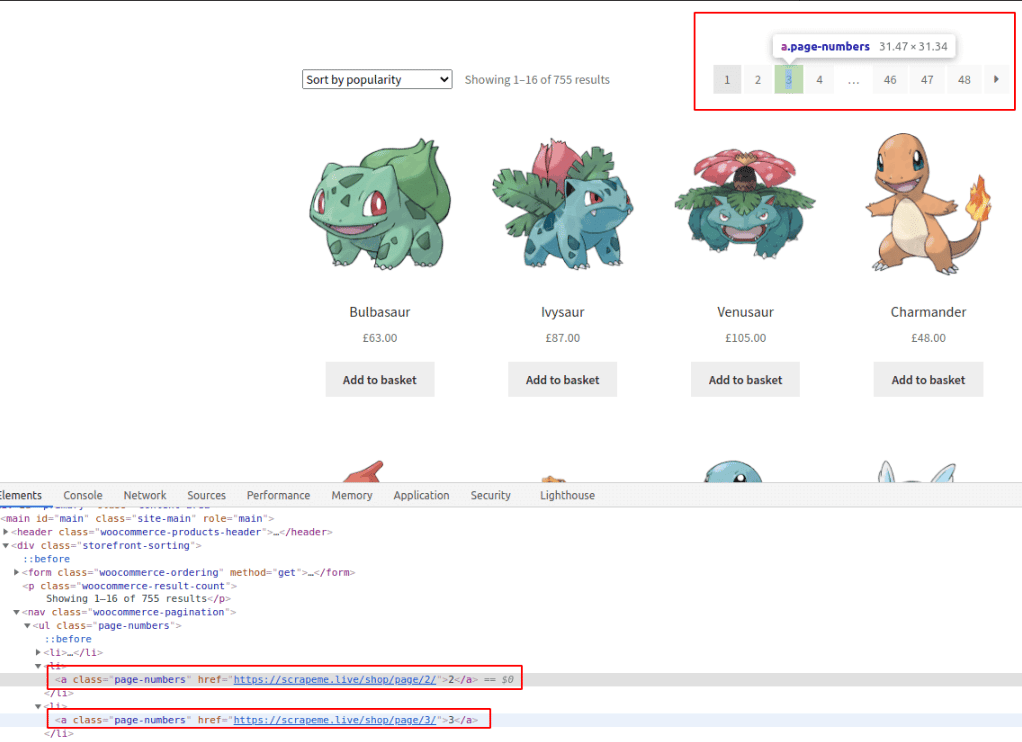
我们用红色标记了有趣的部分,但你们可以自己去尝试。在这种情况下,所有的CSS选择器都是直接的,不需要嵌套。如果你在寻找不同的结果或无法选择,请查看指南。你也可以使用DevTools来获取选择器。
在 “元素 “选项卡上,右击节点➡复制➡复制选择器。但结果通常与HTML非常耦合,如本例中。#main > div:nth-child(2) > nav > ul > li:nth-child(2) > a。
这种方法在将来可能是一个问题,因为它在任何最小的变化后都会停止工作。此外,它只能捕获其中一个分页链接,而不是所有的链接。
你可以在Console标签上执行Javascript,检查选择器是否正常工作。将选择器传递给document.querySelector函数并检查输出。在进行网络爬取时要记住这个技巧。
我们可以捕获页面上的所有链接,然后按内容过滤。如果我们要编写一个全站爬虫,这将是正确的方法。
在我们的案例中,我们只想要分页链接。使用所提供的类,.page-numbers a将捕获它们全部。然后从这些链接中提取URL(hrefs)。CSS选择器将匹配所有具有包含page-numbers类的祖先的链接节点。
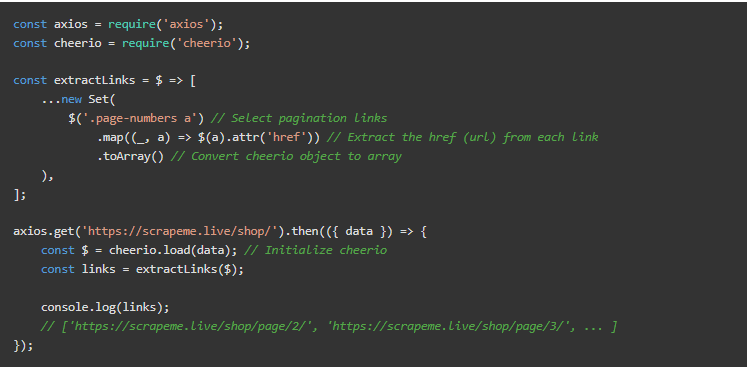
将上述内容存储在一个文件中,并在NodeJS中执行以查看结果。
至于产品(本例中的神奇宝贝),我们将得到id、名称和价格。关于选择器的细节,请查看下面的图片,或者自己再试试。我们现在只记录爬取到的数据。查看最后的代码,将它们添加到一个数组中。
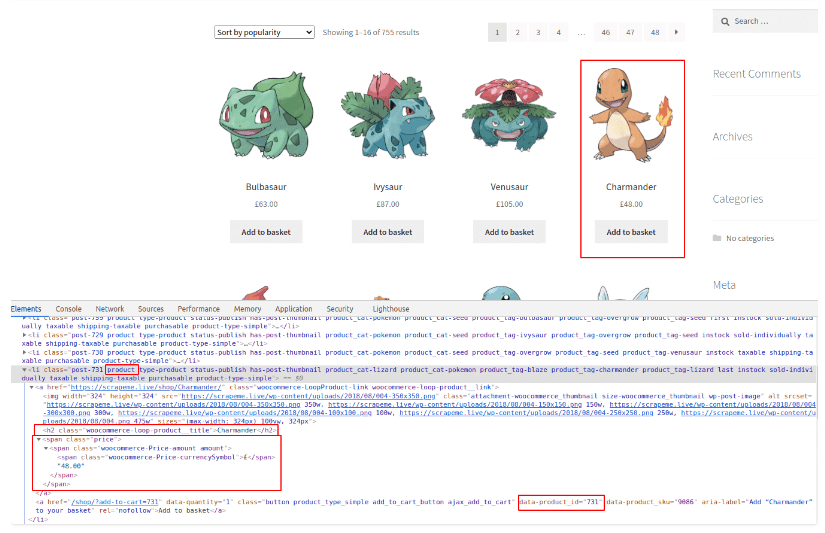
正如你在上面看到的,所有的产品都包含product类,这使我们的工作更容易。而对于每一个产品,h2标签和price节点都包含我们想要的内容。
至于产品ID,我们需要匹配一个属性,而不是一个类或DOM节点类型。这可以用node[attributee="value"]的语法来完成。我们只寻找带有该属性的DOM节点,所以没有必要将其与任何特定的值相匹配。
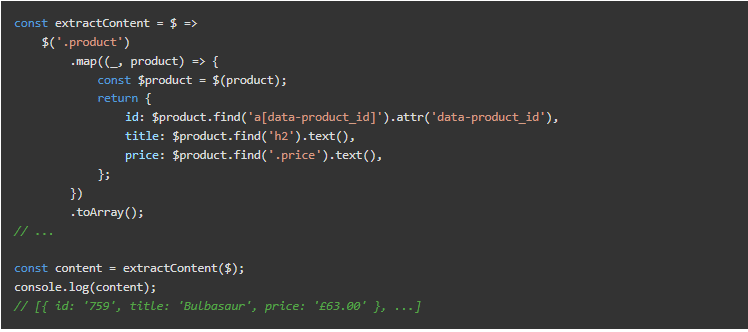
正如你在上面看到的,没有错误处理。为了简洁起见,我们将在片段中省略它,但在实际生活中会考虑到它。大多数情况下,返回默认值(即空数组)就可以了。
以下是与Cheerio API的链接
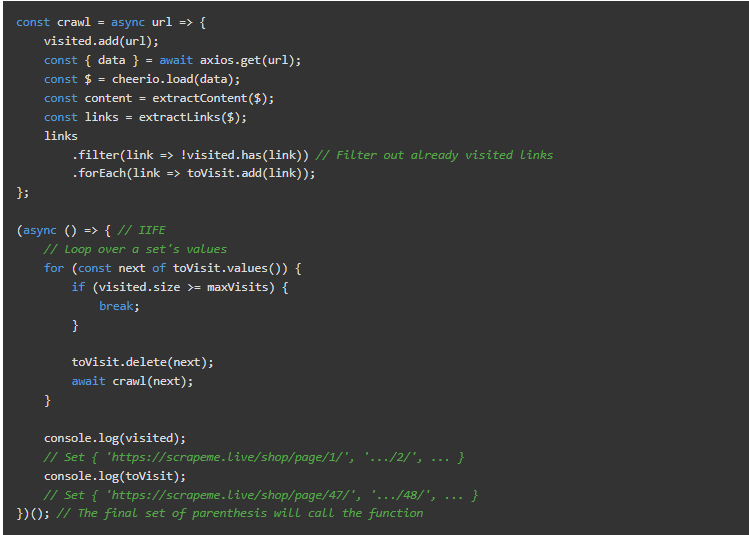
现在我们有一些分页链接,我们也应该访问它们。如果你运行整个代码,你会看到它们出现了两次–有两个分页栏。
我们将添加两个集合来记录我们已经访问过的内容和新发现的链接。自ES2015年以来,Javascript中就有了集合,所有现代NodeJS版本都支持它们。
我们使用它们而不是数组,以避免处理重复的问题,但任何一种都可以。为了避免爬行太多,我们还将包括一个最大值。

我们将在下一部分使用async/await来避免回调和嵌套。async函数是将基于承诺的函数写成链的一种替代方法。同样,在所有现代版本的Node.js中都支持。
在这种情况下,Axios的调用将保持异步。每页可能需要1秒左右,但我们是按顺序写代码,不需要回调。
这里面有一个小问题:await只在async函数中有效。这将迫使我们把初始代码包在一个IIFE(立即调用的函数表达式)里面。这个语法有点奇怪。它创建了一个函数,然后立即调用它。
在网络爬取时避免被拦截
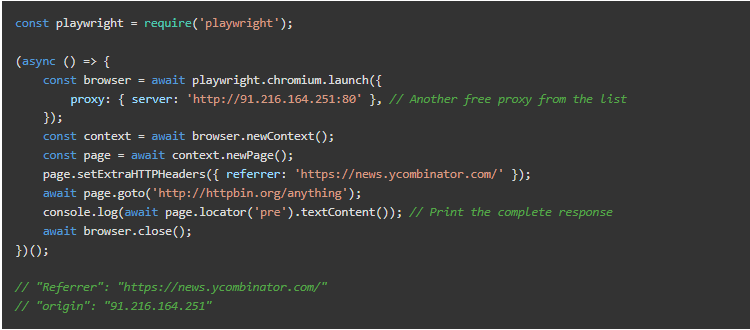
如前所述,我们需要一些机制来避免屏蔽、验证码、登录墙和其他防御性技术。要100%地防止它们是很复杂的。但我们可以通过简单的努力达到很高的成功率。我们将应用两种策略:添加代理和全集头信息。
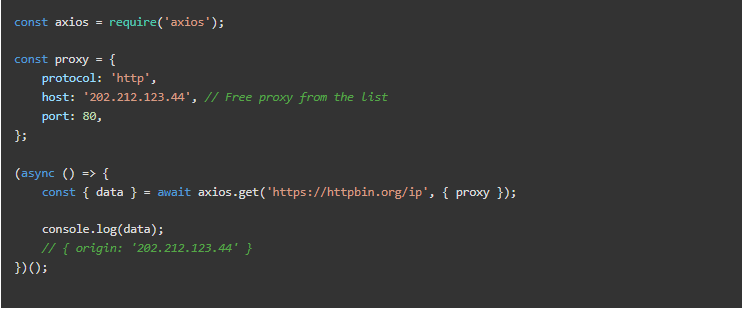
代理服务器
有一些免费代理,尽管我们不推荐它们。它们可能对测试有用,但并不可靠。我们可以使用其中的一些进行测试,正如我们将在一些例子中看到的。
请注意,这些免费代理可能对你不起作用。它们的寿命很短。
另一方面,付费代理服务提供IP旋转。我们的网络爬取器的工作原理是一样的,但目标网站会看到一个不同的IP。在某些情况下,他们对每一个请求或每几分钟进行轮换。在任何情况下,它们都更难被禁止。而当它发生时,我们会在短时间内得到一个新的IP。
我们将使用httpbin进行测试。它提供了一个带有几个端点的API,这些端点将响应头信息、IP地址等。
HTTP请求标头
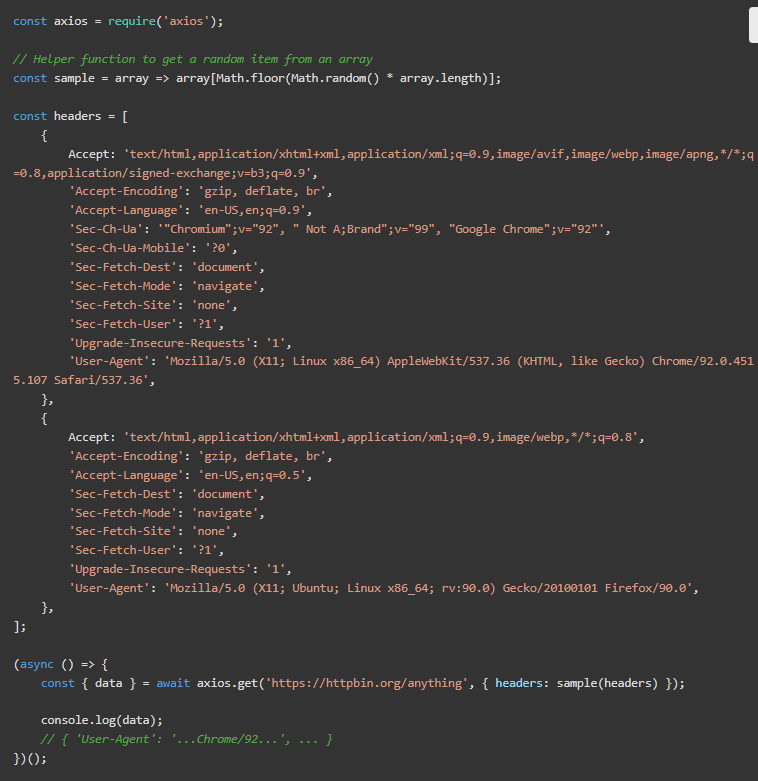
下一步将是检查我们请求的HTTP头。最著名的是User-Agent(简称UA),但还有很多。许多软件工具都有自己的,例如Axios(axios/0.21.1)。
一般来说,在发送UA的同时发送实际的头信息是一个好的做法。这意味着我们需要一套真实的头信息,因为不是所有的浏览器和版本都使用相同的头信息。我们在片段中包括两个。在Linux机器上的Chrome 92和Firefox 90。
用于动态HTML的无头浏览器
到目前为止,每一个访问的页面都是用axios.get完成的,这在某些情况下可能是不够的。假设我们需要JS加载和执行,或者与浏览器互动(通过鼠标或键盘)。
虽然出于性能方面的考虑,避免使用无头浏览器是最好的,但有时也别无选择。Selenium、Puppeteer和Playwright是Javascript和NodeJS世界中最常用和最知名的库。
下面的片段只显示了User-Agent。但由于它是一个真正的浏览器,头信息将包括整个集合(接受、接受-编码,等等)。
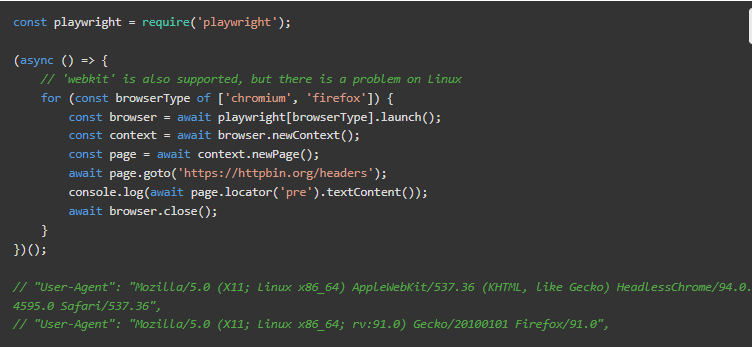
这种方法带来了自己的问题:看看用户代理。Chromium的用户代理包括 “HeadlessChrome”。它将告诉目标网页,嗯,它是一个无头浏览器。他们可能会据此行事。
与Axios一样,我们可以设置头信息、代理和其他选项来定制请求。这是隐藏我们的 “HeadlessChrome “用户代理的绝佳选择。由于这是一个真正的网络浏览器,我们可以拦截请求,阻止其他请求(如CSS文件或图像),拍摄屏幕截图或视频,等等。对于网络爬取来说真的很方便!
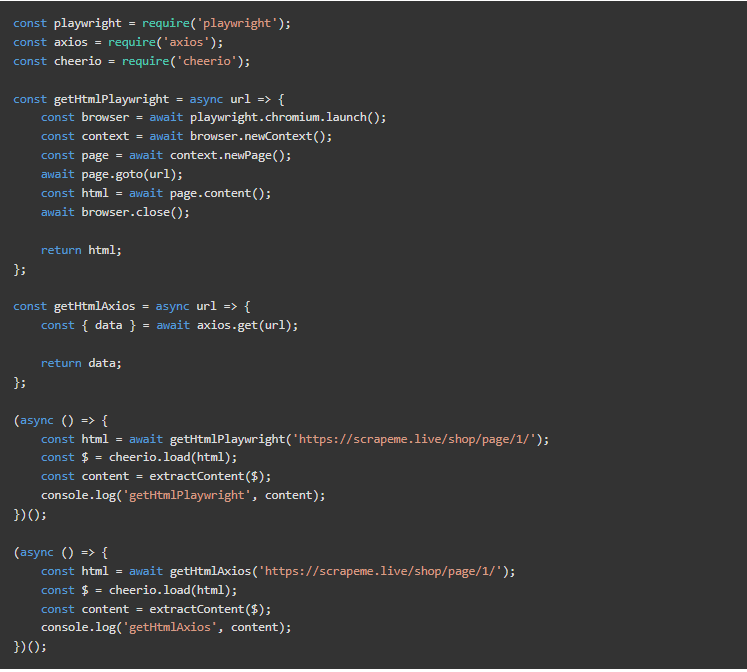
现在,我们可以将获取HTML的工作分成几个函数,一个使用Playwright,另一个使用Axios。然后,我们将需要一种方法来选择哪一个适合手头的情况。现在,它是硬编码的。
顺便说一下,这个输出是相同的,但在使用Axios时相当快。
使用Javascript的async进行平行抓取
我们在顺序抓取几个链接时已经引入了async/await。如果我们要平行地抓取它们,去掉await就够了,对吗?嗯……没那么快。
该函数将调用第一次抓取,并从toVisit集合中取出以下项目。问题是,该集合是空的,因为第一页的抓取还没有发生。所以我们没有向列表中添加新的链接。这个函数一直在后台运行,但我们已经从主函数中退出了。
为了正确地做到这一点,我们需要创建一个队列,在可用时执行任务。为了避免同时出现许多请求,我们将限制其并发性。
Javascript和NodeJS都没有提供内置的队列。对于大规模的网络爬取,你可以搜索那些做得更好的库。
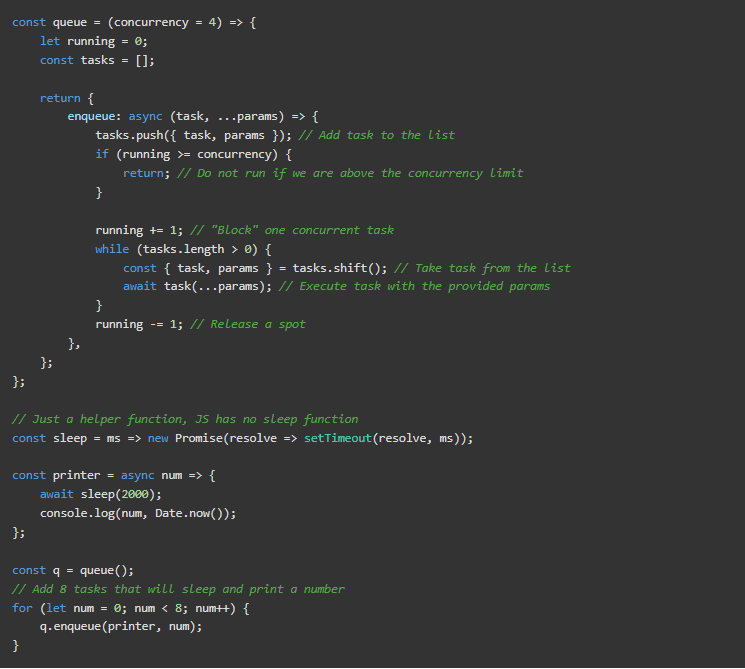
运行上面的代码将几乎立即打印出从0到3的数字(有时间戳)。然后在2秒后从4到7。这可能是最难理解的片段–不急着复习。
我们在第1-20行定义queue。它将返回一个带有函数enqueue的对象,将一个任务添加到列表中。然后它检查我们是否超过了并发限制。如果我们没有,它将把一个任务加到运行中,并进入一个循环,获得一个任务,并以提供的参数运行它。直到任务列表为空,然后从运行中减去1。这个变量是标志着我们什么时候可以或不可以再执行任何任务,只允许它低于并发限制。在第23-28行,有辅助函数sleep和print。在第30行实例化队列,并在第32-34行(将开始运行4)对项目进行enqueue。
你刚刚用JS创建了一个队列,只用了几行代码!
我们现在必须使用队列而不是for循环来同时运行几个页面。下面的代码是部分改变的部分。
记住,Node.js在单线程中运行。我们可以利用它的事件循环,但不能使用多个CPU/线程。我们所看到的效果很好,因为线程大部分时间都是空闲的–网络请求不消耗CPU时间。
为了进一步建立这个,我们需要使用一些存储(数据库、CSV或JSON文件)或分布式队列系统。现在,我们依靠的是Node中线程间不共享的变量。就目前而言,展示爬取到的数据就足以作为一个演示。
它并不过分复杂,但我们在这篇博文中涵盖了足够的内容。
最终代码
所有的代码都在同一个js文件中,用于演示。你可以在Github上看到它。
总 结
我们希望你能分出四个要点。
- 了解网站解析、抓取的基本知识,以及如何提取数据。
- 分清责任,必要时使用抽象。
- 应用所需的技术来避免阻断。
- 能够想出以下步骤来扩大规模。
我们可以使用Javascript和NodeJS建立一个自定义的网络爬取器,使用我们所看到的碎片。它可能无法扩展到数以千计的网站,但对于一些网站来说已经足够了。而向分布式抓取的方向发展,离这里并不遥远,然后再到自动化。