

你是Beautifulsoup的新手吗?那么请阅读下面的文章,了解如何使用它从网页中提取数据。我们提供了最新的一步一步的指南,使你更容易。
使用BeautifulSoup在Python中进行网络抓取的基本步骤。
BeautifulSoup是一个Python库,用于网络抓取,从HTML和XML文件中提取数据。下面是使用BeautifulSoup进行网络抓取的步骤。
1. 安装BeautifulSoup。在终端或命令提示符下使用pip install beautifulsoup4命令来安装 BeautifulSoup 库。
2. 导入库。在你的Python代码中用以下代码导入BeautifulSoup库和request库。
frombs4importBeautifulSoup
importrequests
3. 发送HTTP请求。使用request.get()方法向你想抓取的网页的URL发送一个HTTP请求,并将响应存储在一个变量中。
response = requests.get('https://www.example.com')4. 解析HTML。使用BeautifulSoup函数来解析响应的HTML内容并将其存储在BeautifulSoup对象中。
soup = BeautifulSoup(response.text, 'html.parser')5. 提取数据。使用find()、find_all()和select()等方法,从HTML内容中搜索和提取数据。
title = soup.find('title').text
6. 保存数据。将提取的数据存储在一个变量中,或将其写入一个文件,以便进一步处理。
网络抓取基本上有两个步骤。第一步是发送一个网络请求,以获得一个网页的HTML,而第二步涉及解析并从下载的HTML中提取所需数据。
我们在这篇文章中的重点是第二步–从网页中提取数据。作为一个Python开发者,你会同意我的观点,即除非你有高级知识,否则标准库中包含的标准分析器几乎是不可能使用的。
这导致了对更简单的替代方案的需求,而Beautifulsoup目前是从web psge文档中提取数据的第一大库。它主要与请求一起使用,但有时,开发者也会将其与Selenium一起使用。这篇文章将告诉你如何使用Beautifulsoup从网页中提取数据。
什么是Beautifulsoup?
Beautifulsoup是一个Python网络抓取包,允许解析和抓取HTML和XML页面和文档。在提取数据方面,它是一个相当多样化的工具,因为它可以从你的终端只用几行代码就能分离出网页上的内容。
如果你是一个主要从事网络抓取的python程序员,你可以想象如果没有合适的工具,这项工作将是多么的耗时;这是Beautifulsoup的一个突出特点。重要的是你要知道这个库本身并不是一个分析器。
它利用了一个分析器,如标准的HTML.解析器,甚至是第三方分析器,如lxml.解析器。解析器,甚至是第三方的解析器,如lxml。在提取之前,Python解析器会进行解释,以确保所有的语法都有意义,当BeautifulSoup被用于提取时,数据会被转换为所需的文件类型。
涵盖这个python刮刀的三个主要功能是:它能够提取、导航数据和过滤网页文档内容的值。
用Beautifulsoup解析一个页面
解析是了解如何在Python网络抓取使用Beautifulsoup的关键功能。在本教程的这一部分,我们将向你展示用Beautifulsoup解析一个页面的内容。在这之前,你需要安装Python。我们强烈建议你为本教程安装Pycharm IDE。有一个社区版,你可以免费使用 。
下载并安装PyCharm
在下载用于编码Python的PyCharm之前,重要的是确保你的电脑上已经安装了Python,特别是如果你是用这种语言编程的新手。要安装Python,请遵循下面这些快速步骤。
第1步:访问Python官方网站,这里。有不同的版本可供选择。我们建议你选择最新的版本,因为我们将在本教程中使用该版本。Python(版本3.11.1)。
第2步:当你完成下载后,通过点击 “立即安装 “运行下载的.exe文件,将其安装到你的机器上。
第3步:当安装完成并成功后,你应该看到一个像下面这样的对话框弹出。点击关闭,关闭对话框,完成Python的安装。
下一步将是下载并安装PyCharm。
第4步:要下载PyCharm,请访问这里。
第5步:你应该看到下载专业版或社区版的选项。根据你想要的版本,继续点击下载按钮。在写这篇文章的时候,JetBrains为PyCharm的专业版提供了30天的试用期。
第6步:下载后,运行.exe文件,开始安装。当你看到弹出的安装向导时,点击下一步。
第7步:下面的窗口将显示PyCharm的安装路径。如果有必要,你可以改变路径。点击 “下一步 “继续前进。
第8步:在下面的弹出窗口中,你将获得创建关联、桌面快捷方式、上下文菜单更新、PATH变量更新或所有这些的选择。要继续,选择你想要的选择,然后点击下一步。你可以不选择任何方框而继续。
第9步:在这之后,选择你的开始菜单文件夹。默认情况下,你应该看到JetBrains。你可以让它保持这样的状态,然后点击安装。
第10步。等待几分钟后,安装完成。当它完成后,你应该看到下一个窗口,如下图所示。你可以勾选运行PyCharm 旁边的复选框,然后点击下一步,立即启动PyCharm。
就这样了。我们已经完成了我们需要的 Python IDE 的设置。让我们继续安装我们在本教程中需要的漂亮的汤库。
安装BeautifulSoup
现在Python和PyCharm的安装已经完成,点击创建新项目 开始编写代码,最重要的是安装beautifulsoup库。PyCharm的窗口应该是这样的。
按照下面的指示,开始安装BeautifulSoup。
第1步:要选择它,从菜单栏挑选文件,然后向下滚动到设置。
第2步:设置对话框将弹出。在侧边菜单中,向下滚动选择Project:pythonProject1。 你自己的项目名称可能不同,但你一定会看到Project:下拉菜单。在这之下,选择Python 解释器。要添加一个新的库,点击左上角的加号(+)符号,在软件包列表的上方。
第3步:会弹出一个带有搜索栏的可用套餐窗口。继续前进,在搜索栏中输入beautifulsoup 。会出现一个列表,但要确保选择beautifulsoup4。当你选择完beautiful soup后,点击下面的安装包 。
现在你应该看到它已经在你的 PyCharm Python 包上被更新。点击 确定,然后回到编辑器中导入我们刚刚安装的库。
第四步:在你的编辑器中,输入以下代码
from bs4 import BeautifulSoup
第5步:当你右击编辑器并向下滚动选择“Run Main “时, 你会在PyCharm终端看到以下内容。
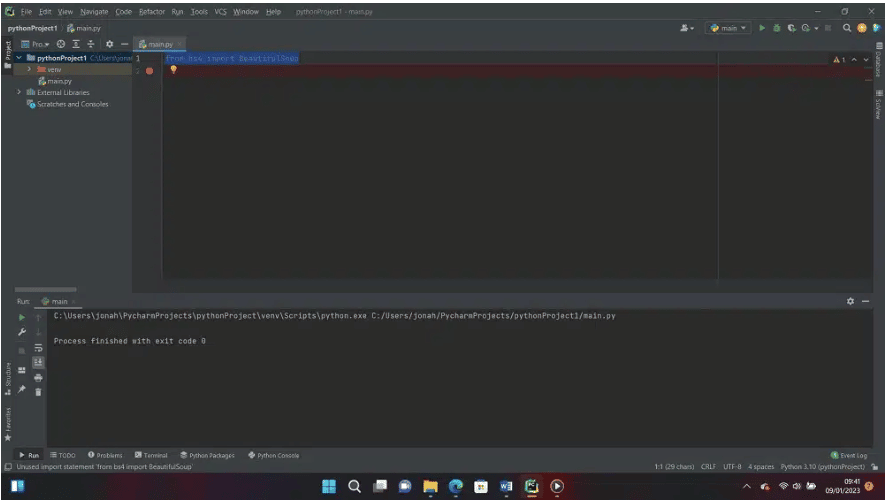
我们已经成功地安装了Beautiful Soup。现在我们将继续在PyCharm IDE中用beautifulsoup进行数据解析。
使用BeautifulSoup来解析一个页面
正如我们前面提到的,beautifulsoup是一个Python库,尤其以解析HTML数据而闻名。然而,在我们继续前进之前,重要的是要知道如何检查我们旨在抓取的网页以及由此带来的好处。
1.检查网站的源代码
在用Beautifulsoup解析一个页面时,检查你想抓取的任何网站的源代码是第一个需要考虑的属性。你应该注意的是,这里有几个约定,它不只涉及一个阶段。
检查任何网站的源代码是非常关键的,在进行精确的抓取任务之前应该清楚地了解,为什么,因为一个错误会导致错误的提取或收集数据。
然而,在你开始编写任何Python代码之前,你必须先熟悉你想获取数据的网站,了解他们设计网站的方式以及实现你的目标所需的一切。之后,尝试用你选择的浏览器打开网站,并进行以下操作。
2.探索网站
在这种情况下,探索只是在网站周围走一走。例如,你是一个数字营销人员,打算抓取一个电子商务商店,以了解竞争对手目前的价格表和运营标准或模块的操作方法。
打开访问网站后,你点击进入,从事任何重要的活动,就像其他客户会做的那样。检查商品的价格,滚动阅读指南和一切需要帮助你在网站上找到你的方式。
尽量想购买一些东西,看看设计和结构以及价格价值看起来如何。这一点很重要,因为你搜索得越多,你就有可能找到更多的描述性和详细的信息。
此外,你点击的每一个主页、服务和关于我们的页面细节都会改变URL。这一点应该引起注意,因为这将有助于简化你的主要目标,并扩大你对网站地址和语法变化的理解。
3.解密URL中的信息
如果上述功课做得正确,你就可以去解码、解释或阅读网址,以熟悉URL的接线方式。我们不要忘记,如果你是一个程序员,试图从你感兴趣的网站上抓取数据,这一点是不可或缺的。
请记住,这适用于整个网站,因为如果你对它一无所知,或者没有做广泛的研究来探索这个网站,你的抓取驱动程序将被打败。
要阅读任何URL,你必须了解URL的结构。这意味着,URLs中携带HTML文件的部分与精确搜索的部分不同。具体的文件位置是最重要的,因为它是网站的独特资源所在。
以你在浏览器上打孔为例,http://www.amazon.com,当网站打开时,你点击客户服务,网站的URL将变为这个链接。
你可以看到,与你最初加载的内容相比,有一个明显的区别。这告诉你,URL可以是相同的,但你所追求的精确参数有其独特性。如果你点击 “今日优惠”,URL会出现相同的HTML,但有不同的HTML。
然而,在访问任何网站时,URL是一个大问题,因为其查询参数有独特的语法。因此,你与网站的互动越多,你看到的变化就越多。一个URL的查询参数由三个属性组成:开始、数据和分隔符。
因此,当你能正确分析你的目标网站的URL时,你的任务就变得更加容易。让我们使用三个查询属性来分析上述客户服务URL的查询参数。
Start
Start告诉你具体的HTML细节的开始点。问号语法(?)用来表示它。请注意这一点。
Data
Data描述了特定的URL查询参数所包含的信息,它是由赋值运算符,即等号(=)来编码的。这种语法经常将连接在一起的键和值连接起来。
Separator
这是在键值和ref之间的安培号。URL的一个有趣的特点是它能够在每个命令中改变,所以要确保你理解这个语法。它将帮助你正确地进行抓取。
使用开发者工具来检查网站
在检查任何网站时,要考虑的另一个参数是开发者工具,你打算抓取。
正如上文所述,了解你打算抓取的网站的结构是重中之重,因为这是一个决定因素。这种情况就是开发人员工具发挥作用的地方。开发者工具将帮助你了解你要抓取的网站的结构。有趣的是,每个高级浏览器都安装了这个工具,尽管它在系统类型上有所不同。它在Windows和Linux上不像在macOS上那样容易获得。
要在Chrome浏览器中打开开发者工具,请打开浏览器右上角的Chrome菜单,选择更多工具>开发者工具。另外,在macOS上,你可以使用Option + ⌘ + J来访问其快捷方式,而在Windows和Linus上,你可以使用Shift + CTRL + J来获得快速访问。
通过ID查找元素
在检查了页面之后,通过ID寻找元素是相当容易和直接的。只要确保你的漂亮的汤库已经安装并且是最新的。
第1步:我们要做的第一件事是导入BeautifulSoup库。
from bs4 import BeautifulSoup
第2步:下面的步骤是向库中添加请求。这是获取我们的目标页面的源代码的好时机。在这种情况下,URL是https://amazon.com。要做到这一点,请输入以下代码。
import requests
r = requests.get ("https://www.amazon.com/s?k=gaming+mouse")
第3步:你应该把HTML代码转换成BeautifulSoup对象,俗称soup。
soup = BeautifulSoup(r.content,"html.parser")
第4步:确保交叉检查你打算解析的特定ID。这很重要,因为元素的ID是唯一的。因此,我们将使用查找方法。你可以使用soup.find all(id=”value”),但由于其ID是唯一的,你可以直接使用soup.find all(id=”value”)。此外,定位它应该不是那么困难。下面的代码显示了如何完成它。
element_by_id = soup.find("div", {"id":"a-page"})
你会注意到,在上述代码中,我们首先声明了标签,然后才声明了ID。
整行代码应该是这样的。
from bs4 import BeautifulSoup
import requests
r= requests.get ("https://www.amazon.com/s?k=gaming+mouse")
soup = BeautifulSoup(r.content,"html.parser")
element_by_id = soup.find("div", {"id":"a-page"})
按类名查找元素
同样地,你仍然可以通过类名来选择HTML元素。这一次,你必须使用find_by_class方法。代码应该像下面这样。
from bs4 import BeautifulSoup
import requests
r=requests.get ("https://www.amazon.com/s?k=gaming+mouse")
soup=BeautifulSoup(r.content,"html.parser")
element_by_class=soup.find("div", class_="a-size-medium")
提取HTML元素中的文本
假设你对从网页上刮取段落感兴趣。使用我们前面讨论的请求和bs4方法,Python的BeautifulSoup库可以协助你获得。
import module
import requests
from bs4 import BeautifulSoup
# link for extract html data
def getdata(url):
r = requests.get(url)
return r.text
htmldata = getdata("# import module
import requests
from bs4 import BeautifulSoup
# link for extract html data
def getdata(url):
r = requests.get(url)
return r.text
htmldata = getdata("https://blog.casaomnia.it/en/indispensable-kitchen-utensils/")
soup = BeautifulSoup(htmldata, 'html.parser')
data = ''
for data in soup.find_all("p"):
print(data.get_text())
")
soup = BeautifulSoup(htmldata, 'html.parser')
data = ''
for data in soup.find_all("p"):
print(data.get_text())
上面的代码中的方法是导入一个模块,然后创建一个HTML文档。在此,我们可以在代码中指定<p>标签。
接下来是将HTML文档传入beautifulsoup()函数,然后使用P标签从beautifulsoup对象中提取段落。同时,get_text()帮助从HTML文档中获取文本。
将数据导出到CSV文件
现在我们已经了解了如何传递HTML和XML数据,现在是时候看看如何保存你抓取到的数据供以后使用。
首先,我们需要安装Pandas库。这个库帮助Python存储和生成结构化数据。要安装这个库,你可以按照我们为BeautifulSoup库所做的步骤,或者添加以下几行代码。
代码:
pip install pandas
or
#Add this to your code.
import pandas as pd
安装完Pandas后,输入下面的代码,将你的数据导出到CSV。
import pandas as pd
from bs4 import BeautifulSoup
path = 'https://www.iban.com/dialing-codes.html'
data = []
# To get the header from the HTML file
list_header = []
soup = BeautifulSoup(open(path), 'html.parser')
header = soup.find_all("table")[0].find("tr")
for items in header:
try:
list_header.append(items.get_text())
except:
continue
# Fetching the data
HTML_data = soup.find_all("table")[0].find_all("tr")[1:]
for element in HTML_data:
sub_data = []
for sub_element in element:
try:
sub_data.append(sub_element.get_text())
except:
continue
data.append(sub_data)
# Storing the data into Pandas DataFrame
dataFrame = pd.DataFrame(data=data, columns=list_header)
# Converting Pandas DataFrame into CSV file
dataFrame.to_csv('Tables.csv')
用这两种方法中的任何一种成功导入Pandas库后,beautiful会帮助获取HTML文件中的文件头,然后再去获取表格数据。然而,为了存储这些数据,我们需要潘达斯库。这里我们介绍库的DataFrame来存储CSV格式的数据。
关于Beautifulsoup指南的常见问题
1.BeautifulSoup是一个Python模块吗?
是的,BeautifulSoup 是一个 Python 模块。它被用来解析和刮取HTML和XML文件中的数据。作为一个主要从事互联网数据抓取或提取的程序员,你可以想象,如果没有合适的抓取工具集来进行这项活动,将是多么的疲惫和费时。
因此,当你使用像Beautifulsoup这样专门为刮取复杂多样的HTML网站而设计的工具时,花费的时间会更少,你的目标也会更有成效地实现。
2.我需要安装Beautifulsoup吗?
Beautifulsoup不在标准库中,因此,在使用它提取任何数据之前,需要安装它。Beautifulsoup支持Python标准库中的一个HTML解析器。此外,它还支持许多其他的外部Python解析器,如LXML解析器,以及其他Python解析器。更重要的是,在本教程中,你亲身体验了如何安装这个Python抓取工具。
总 结
从网页文件中解析重要的数据可能是很困难的,因为HTML页面是由设计者编写的,性质很乱。作为一个Python网页抓取器的开发者,你不需要太担心这些复杂的问题,因为Beautifulsoup可以帮助你解决相关的困难。
上面的指南向你展示了如何简单地使用Beautifulsoup库。你应该阅读Beautifulsoup的官方文档来学习如何详细地利用它和更复杂的用法。

